پیشرفت فناوری تشخیص صدا (voice recognition) در بریتانیا برای مبتلایان به اختلال گفتار نویدبخش است، تحقیقات انجام شده توسط متخصصان دانشگاه گلاسکو می تواند منجر به توسعه فناوری های جدید سنتز صدا برای افراد مبتلا به اختلالات گفتاری شود.
این تیم با تجزیه و تحلیل فرآیندهای فیزیکی که صداهای گفتار را ایجاد می کند، مجموعه داده ای ساخته است که می تواند زیربنای توسعه سیستم های تشخیص گفتار باشد که می توانند لب ها و حرکات صورت افراد مبتلا به اختلالات گفتاری را بخوانند و صدایی ترکیبی برای آنها فراهم کنند.
برای جمع آوری داده های خود، گروه تحقیقاتی - که شامل محققی از دانشگاه داندی و دانشگاه کالج لندن است - از 20 داوطلب خواست که یک سری صداهای مصوت، تک کلمات و جملات کامل را در حین اسکن پیچیده حرکات صورت و ضبط صدای آنها ادا کنند.
سپس این تیم از دو فناوری راداری مختلف - امواج رادیویی فوق عریض (IR-UWB) و موج پیوسته مدوله شده فرکانس (FMCW) - برای تصویربرداری از حرکت پوست صورت داوطلبان در حین صحبت کردن، همراه با حرکات زبان و حرکت آنها استفاده کرد.
همزمان با حنجره، ارتعاشات روی سطح پوست آنها با یک سیستم تشخیص لکه لیزری اسکن می شود که از یک دوربین با سرعت بالا برای ثبت ارتعاش لکه های لیزری ساطع شده استفاده می کرد.
یک دوربین Kinect V2 مجزا که قادر به اندازهگیری عمق است، تغییر شکلهای دهان آنها را هنگام شکل دادن صداهای مختلف میخواند.
به گفته گروه تحقیقاتی این کار میتواند دستگاههای کنترلشده صوتی مانند تلفنهای هوشمند را قادر سازد تا لبهای کاربران را هنگام صحبت کردن در سکوت بخوانند.
بهبود کیفیت تماسهای ویدیویی و تلفنی در محیطهای پر سر و صدا و حتی کمک به بهبود امنیت برای تراکنشهای بانکی یا محرمانه با تجزیه و تحلیل حرکات منحصر به فرد صورت کاربران قبل از باز کردن قفل اطلاعات ذخیرهشده حساس از جمله کارایی های این فناوری خواهد بود.
پروفسور محمد عمران، رهبر مرکز ارتباطات حسگری و تصویربرداری دانشگاه گلاسکو گفت: حسگر بدون تماس پتانسیل زیادی برای بهبود تشخیص گفتار و ایجاد برنامههای کاربردی جدید در ارتباطات، مراقبتهای بهداشتی و امنیت دیجیتال دارد.
وی افزود: ما مشتاقیم در گروه تحقیقاتی خودمان در دانشگاه گلاسکو بررسی کنیم که چگونه میتوانیم با استفاده از حسگرهای چندوجهی پیشرفتهای جدید را در لب خوانی ایجاد کنیم و کاربردهای جدیدی در همه جا از خانهها تا بیمارستانها پیدا کنیم.
مجموعه داده چندوجهی جامع برای لب خوانی بدون تماس و آنالیز آکوستیک
تشخیص حرکت در مقیاس کوچک با استفاده از تکنیکهای سنجش از راه دور غیرتهاجمی اخیراً در زمینه تشخیص گفتار مورد توجه قرار گرفته است.
به طور خاص مجموعه داده شامل دادههای واکنش ضربهای کانال 7.5 گیگاهرتز (CIR) از رادارهای باند فوقعرض (UWB)، دادههای موج پیوسته مدولهشده با فرکانس 77 گیگاهرتز (FMCW) از رادار موج میلیمتری (mmWave)، اطلاعات دیداری و صوتی، نشانههای لب (لب خوانی) و داده های لیزری می باشد و بصورت یک رویکرد چندوجهی منحصر به فرد برای تحقیقات تشخیص گفتار ارائه شده است.
در همین حال یک دوربین عمیق برای ضبط نقاط عطف لب و صدای سوژه در نظر گرفته شده است که تقریباً 400 دقیقه از نمایههای گفتار مشروح ارائه شده است که از 20 شرکتکننده جمعآوری شده است که با 5 مصوت، 15 کلمه و 16 جمله صحبت میکنند.
مجموعه داده تایید شده است و پتانسیلی برای بررسی لب خوانی و تشخیص گفتار چندوجهی دارد.
در وظایف کلی تشخیص گفتار، اطلاعات صوتی از میکروفون ها منبع اصلی برای تجزیه و تحلیل ارتباطات کلامی انسان است.
فرآیند گفتار فقط وسیله ای برای انتقال اطلاعات زبانی نیست، بلکه می تواند بینش ارزشمندی را در مورد ویژگی های گوینده مانند جنسیت، سن، منشاء اجتماعی و منطقه ای، سلامت، وضعیت عاطفی و در برخی موارد حتی هویت آنها ارائه دهد.
اخیراً تکنیک تشخیص خودکار گفتار (ASR) به بلوغ رسیده و به بازار عرضه شده است و علاوه بر سیگنالهای صوتی، مجموعهای از فرآیندهای فیزیولوژیکی که صدا تولید میکنند، مانند حرکت لب، لرزش تارهای صوتی و حرکت سر، اطلاعات معنایی و گوینده را نیز تا حدی حفظ میکنند.
از سوی دیگر دو محدودیت اصلی در محیطهای خاص وجود دارد که فقط اطلاعات صوتی نمیتوانند برای ASR به طور کامل کار کنند: تشخیص گفتار بیصدا (SSR) و محیطهای چند بلندگو، هر دو موضوع با در نظر گرفتن ویژگی های فیزیک سخنران قابل حل است و در پاراگراف های بعدی توضیح داده خواهد شد.
SSR را می توان شاخه مهمی از تشخیص گفتار در نظر گرفت که روش های ارتباطی قابل درک و تقویت کننده ای را برای کمک به بیماران مبتلا به اختلالات گفتاری شدید ارائه می دهد.
در سالهای اخیر تحقیقات در زمینه تشخیص گفتار بیصدا، رویکردهای مختلفی از جمله حسگرهای پوشیدنی، سیستمهای مبتنی بر رادار و سایر تکنیکهای غیرتهاجمی را برای مقابله با چالشهای ضبط و پردازش اطلاعات مربوط به گفتار بررسی کردهاند.
روشهای تماسی عمدتاً بر تشخیص فعالیت مغز و ماهیچه با حسگر الکتروانسفالوگرام (EEG)، هدست حرکات مفصلکننده و انواع دیگر حسگرهای قابل کاشت تمرکز دارند و با این حال روشهای مبتنی بر تماس به شدت به حسگرهای پوشیدنی و ایمپلنتی وابسته هستند، که به بیماران اختصاص داده شده است اما مجموعه دادهای بزرگ از یک فرد عادی جمعآوری نمیکند.
و کاربران باید خطرات بالقوه سلامت دستگاه های قابل تماس را در نظر بگیرند.
برای اختلال صدا و سایر بیمارانی که توانایی کنترل ارتعاش تارهای صوتی و عضلات صورت را با کمک دستگاه های مختلف حفظ می کنند، SSR غیرتهاجمی این پتانسیل را دارد که کیفیت زندگی آنها را در مقایسه با حسگرهای الکترونیکی بهبود بخشد.
علاوه بر این در سناریوهایی با چند بلندگو، میکروفون صداهای اطراف را بدون تشخیص هویت فرد ضبط میکند که دقت تشخیص گفتار را بهطور جدی کاهش میدهد و این موضوع شبیه به کوکتل پارتی افکت4 است که پدیده ای است که در آن یک فرد می تواند با وجود احاطه شدن توسط چندین مکالمه همزمان روی یک مکالمه تمرکز کند.
این اثر عمدتاً به توانایی مغز در پردازش فرکانس شنوایی و برجسته کردن صداهای خاص نسبت داده میشود، که به فرد اجازه میدهد بر منبع مورد علاقه تمرکز کند بدون اینکه به راحتی حواسش پرت شود، با این حال جدا کردن منابع مختلف تنها با استفاده از دادههای صوتی یک چالش است.
در این حالت دستگاه های رادار یا لیزر اضافی می توانند به مدل در تشخیص صدا با توجه به اطلاعات فیزیکی کمک کنند.
برای مثال work5 پیشنهادی سیگنالهای صوتی و رادار را برای فیلتر کردن پس از نویز اضافه ترکیب کرد و ثانیاً، اطلاعات صوتی از جمله لحن و عادات صحبت کردن افراد حاوی انواع دادههای شخصی است که میتوان از آنها برای ایجاد یک اثر انگشت صدای منحصر به فرد مانند عادات صحبت کردن و لحن استفاده کرد.
این امر باعث خطر نشت داده های حساس می شود، زیرا اثر انگشت صدا می تواند برای شناسایی استفاده شود.
برای الگوریتم مبتنی بر حسگر بیسیم، لرزش تارهای صوتی تنها بر لحن گفتار متمرکز میشود، که شامل اطلاعات حریم خصوصی نمیشود.
تحقیقات قبلی تشخیص گفتار عمدتاً بر روی حرکات دهان مبتنی بر بصری متمرکز شده است، که خطر کمبود حریم خصوصی و نادیده گرفتن حرکات داخلی دهان را به همراه دارد.
در این مقاله مجموعه دادهای از گفتار انسان را با جمعآوری دادهها از اطلاعات حسگرهای متعدد در حالی که افراد در حال صحبت کردن بدنه خاصی هستند، پیشنهاد شده است و مشارکت مجموعه داده در موارد زیر به پایان می رسد:
در این کار یک مجموعه داده جدید را ارائه میدهیم که روشهای متعددی را برای تشخیص گفتار بیصدا، از جمله رادارهای باند فوقعرض (UWB)، رادار موج میلیمتری (mmWave) و دادههای دوربین عمقی را در بر میگیرد، که معتقدیم منبع ارزشمندی برای محققان در این زمینه خواهد بود.
انتظار میرود این مجموعه داده، کار محققانی را که انتظار دارند روی SSR از سیگنالهای بیسیم یا تقویت سیگنالهای صوتی کار کنند، کاهش دهد.
این سیستم حرکات فیزیکی تمام قسمت های سر را در حین گفتار انسان از جمله حرکات دهان و ارتعاشات تارهای صوتی را در نظر می گیرد.
طیف متنوعی از روشهای موجود در مجموعه داده فرصتهای زیادی را برای انجام تحقیقات در زمینه تشخیص گفتار ارائه میدهد و این محدوده شامل موارد زیر است، اما به آن محدود نمی شود:
طبقه بندی حروف صدادار و کلمات مبتنی بر رادار، شناسایی گوینده، تقویت گفتار در محیط پر سر و صدا، بازسازی لب مبتنی بر رادار و غیره.
روش و نحوه اجرا
در مرحله اول یک بررسی متون انجام دادیم تا حسگرها و تنظیمات آزمایشی لازم را برای تشخیص گفتار مبتنی بر رادار، با توجه به عدم وجود استاندارد و پیکره، ایجاد شده و در همین حال در دسترس بودن همه حسگرهایی را که اتخاذ کرده و نشان میدهیم و سپس رویکرد جمعآوری دادههای خود را با ارجاع به کارهای قبلی ایجاد میکنیم.
بررسی ادبیات تشخیص گفتار با رادار فعال
انواع مختلفی از حسگرها برای تحقیقات گفتار به کار گرفته شده است: UWB، رادار mmWave و آشکارساز لکه لیزری برای کار SSR، کار UWB کار لب خوانی را با حروف صدادار [æ]، [i]، [ә]، [ɔ:]، [u:] و سناریوی ایستا، با ماسک صورت نشان داد.
نتیجه 95% تایید می کند که حرکت دهان سیگنال های اطلاعاتی برای سنجش UWB تولید می کند. رادار FMCW نیز یک انتخاب اختیاری است که در نتیجه مقاله ثابت شده است. اثر مذکور ابرهای نقطهای از دهان انسان در حین صحبت کردن را به عنوان ویژگی داده برای طبقهبندی کار 13 کلمهای با 4 سخنران استفاده میکند.
با استفاده از طبقهبندیکنندههای رگرسیون خطی، دقت 88 درصد را به دست میآورد. برای گسترش کار و بهره برداری از امکانات بیشتر، جملاتی را برای جمع آوری داده ها در مورد مرجع اضافه کردیم.
علاوه بر این، رادار mmWave FMCW برای تقویت گفتار در آثار منتشر شده استفاده شده است.
این دو تحقیق جهتهای فوکوس مشخصی دارند: مقاله 5 ضریب فاصله را برای سیگنالهای رادار در نظر گرفته و با موفقیت پیادهسازی سیستم تقویت گفتار را در 7 متر انجام میدهد و 6،9 بر روی جداسازی صوتی چند بلندگو با اطلاعات مکانی مبتنی بر رادار کار می کند.
برای اطلاعات مرتبط با لیزر، paper10 یک روش اندازه گیری از راه دور را برای افراد سالم پیشنهاد کرد که شامل گرفتن لکه لیزر منعکس شده از سطح پوست گردن است.
این سیستم قادر است ریز ارتعاشات ناشی از فشار خون را روی سطح گردن ثبت کند که میتواند برای استخراج سیگنالهای صوتی بدون سیگنال صوتی از طریق تشخیص لرزش ناشی از گلو نیز استفاده شود.
با الهام از آثار ذکر شده، تصمیم گرفتیم حسگرهای راداری رادار FMCW و رادار UWB، سیستم تشخیص لکه لیزری و دوربین Kinect را برای جریان اسکلت دهان و صدای گفتار به عنوان منبع مجموعه داده چندوجهی خود بکار گیریم.
علاوه بر این، مجموعه دادههای مربوط به کارهای تشخیص گفتار مبتنی بر چندوجهی را در جدول 1 نتیجهگیری میکنیم. تا جایی که میدانیم، بیشتر مجموعه دادههای دسترسی باز در تشخیص گفتار به جای در نظر گرفتن سیگنالهای رادیویی، بر موضوعات سمعی و بصری تمرکز میکنند.
اگرچه تحقیقاتی در مورد پردازش گفتار مبتنی بر سیگنال های بی سیم صحبت شده است، دریافت مجموعه داده از نویسندگان دشوار است. بنابراین، سهم اصلی ما ایجاد یک مجموعه داده گفتاری بدون تماس برای تحقیق در مورد ترکیب سیگنالهای صوتی و ارتعاش فیزیکی از سیگنال بیسیم است.
طرح اکتساب داده
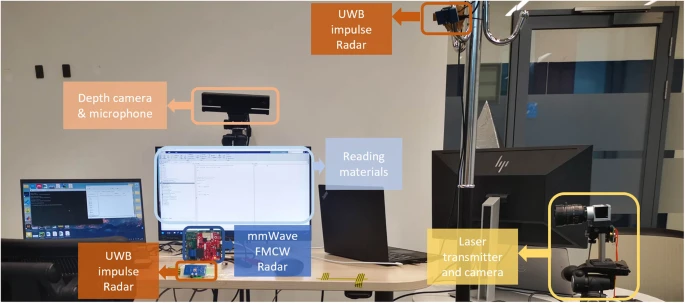
سیستم جمعآوری اطلاعات کلی توسط چهار لپتاپ و چهار نوع حسگر سازماندهی شد: Microsoft Kinect V2 برای صدا و تصویر از جمله نقطه عطف دهان، رادار X4M03 UWB از NOVELDA، رادار AWR2243 mmWave از Texas Instrument و سیستم اندازهگیری لیزری برای ارتعاش فیزیکی گفتار انسان.
انتخاب دستگاه ها از تحقیقات قبلی ذکر شده ارجاع شده است. برای همگامسازی دادهها با سنسورهای مختلف، از اتصال TCP/IP برای کنترل لپتاپهای میزبان مجزا با همان پروتکل زمان شبکه (NTP) برای ضبط مهر زمانی در حین جمعآوری دادهها استفاده کردیم.
یک اسکریپت کنترل چند رشته ای توسعه یافته و به کار گرفته شده است که به طور خودکار اسکریپت های ضبط داده را شروع و پایان می دهد و تأخیر ثبت داده ها را تا حد زیادی به حداقل می رساند.
هنگامی که اسکریپت را روی لپ تاپ اصلی اجرا می کنیم، Master دستورات را به سه سوکت دیگر به صورت سری ارسال می کند و میانگین تأخیر از Master به سوکتهای دستگاههای دیگر حدود 80 میلیثانیه است که در پردازش پس از همگامسازی ما در نظر گرفته میشود.
علاوه بر این، ما از نظارت متخصص و کالیبراسیون دستی برای اطمینان از همگام سازی زمان در سنسورهای مختلف استفاده کردیم. ما دستگاه ها را کالیبره کردیم، روند جمع آوری داده ها را زیر نظر گرفتیم و تنظیمات لازم را در کل مجموعه داده ها انجام دادیم.
با توجه به تحقیقات بالقوه برای تشخیص گفتار، ما سه طرح جمع آوری داده را طراحی کردیم که در زیر نشان داده شده است و مجموعه پذیرفته شده در یک پوشه اضافی در مجموعه داده ما ثبت می شود.
گفتار تک نفره از حروف صدادار، کلمات و جملات.
گفتار دو نفره به طور همزمان از جملات پیچیده.
گفتار تک نفره از حروف صدادار، کلمات و جملات با فاصله متفاوت از رادار تا بلندگو.
جزئیات جمعآوری دادهها از حسگر خاص در زیر نشان داده شده است، با تنظیم آزمایش نشان داده شده در شکل 2.
صدای گفتار
از Kinect v2 برای جمع آوری گفتار صوتی استفاده کردیم. با فعال کردن Kinect v2 برای جمع آوری اطلاعات صوتی دقیق. نرخ نمونه داده های صوتی 16 اینچ کیلوهرتز و عمق بیت 16 بیت است.
محدوده فرکانس ضبط صدا تا 8 اینچ کیلوهرتز است که می تواند محدوده فرکانس صدای انسان را پوشش دهد.
نقاط اسکلتی دهان
Kinect v2 همچنین در جمع آوری اطلاعات نشانه های چهره استفاده می شود. یک دوربین RGB و یک دوربین مادون قرمز در kinect v2 ادغام شده اند. با اندازهگیری زمان پرواز (ToF) با استفاده از دوربین IR کینکت میتواند عمق تصویر را دریافت کند.
در همین حال ما از روش تشخیص لب پیشنهاد شده در مقاله 11 برای استخراج اسکلت لب استفاده می کنیم که به عنوان بخشی از مجموعه داده ما ارائه شده است.
رادار IR-UWB
مانند Wi-Fi و بلوتوث، UWB یک پروتکل ارتباطی بی سیم با برد کوتاه است. UWB به عنوان سیستم انتقال بی سیم تعریف شد که پهنای باند آن از 500 مگاهرتز فراتر می رود و هر پالس ارسالی این سیستم ارتباطی می تواند حداقل 500 مگاهرتز پهنای باند را اشغال کند.
IR-UWB به جای تعدیل با موج حامل، به سیگنالهای رادیویی ضربه باریک غیر سینوسی نانوثانیه (ns) تا پیکوثانیه (ps) برای انتقال دادهها متکی است. فن آوری مدولاسیون مبتنی بر زمان سرعت انتقال را افزایش می دهد و مصرف برق را کاهش می دهد.
سیستم UWB برای تشخیص گفتار دارای مزایای زیر است:
توانایی ضد تداخل قوی:
از مکانیسم RF، موج پالسی ساطع شده توسط UWB نسبت به امواج الکترومغناطیسی پیوسته در برد کوتاه در برابر تداخل مقاومتر است به طور خاص، باند فرکانس کاری مجاز UWB از 3 گیگاهرتز تا 10 گیگاهرتز است که از اختلالات کمتری از سیستم WiFi عمومی 2.4 گیگاهرتز و سایر سیگنال های مخابراتی رنج می برد.
این پروتکل نتایج مثبتی را به همراه داشت که منجر به کاهش مصرف برق برای کاربردهای ارتباطی کوتاه برد شد و قدرت انتقال فرستندههای UWB که معمولاً کمتر از 1 میلیوات است که زمان عملکرد سیستم را افزایش میدهد و تابش امواج الکترومغناطیسی را به بدن انسان به حداقل میرساند.
پس از بررسی دقیق هزینه و امکان سنجی، ما XeThru X4M03، یک سیستم راداری IR-UWB روی تراشه، را به عنوان رادار UWB خود انتخاب کردیم و مشخصات UWB RF این رادار توسط ETSI (موسسه استانداردهای مخابراتی اروپا) در اروپا و FCC (کمیسیون ارتباطات فدرال) در ایالات متحده برای استفاده تجاری در شرایط زندگی انسان تایید شده است.

رادار IR-UWB توانایی تشخیص اجسام در برد تا 10 متر را دارد همچنین قادر است اجسام را در طیف وسیعی از زوایای تا 180 درجه تشخیص دهد، این سیستم راداری در انواع پروژه های تحقیقاتی، از تشخیص علائم حیاتی انسان تا تشخیص فعالیت به کار گرفته شده است.
لینک سایت مرجع
مالکیت معنوی مجله انرژی (energymag.ir) علامت تجاری ناشر است... سایر علائم تجاری مورد استفاده در این مقاله متعلق به دارندگان علامت تجاری مربوطه می باشد، ناشر وابسته یا مرتبط با دارندگان علامت تجاری نیست و توسط دارندگان علامت تجاری حمایت، تایید یا ایجاد نشده است، مگر اینکه خلاف آن ذکر شده باشد و هیچ ادعایی از سوی ناشر نسبت به حقوق مربوط به علائم تجاری شخص ثالث وجود ندارد.